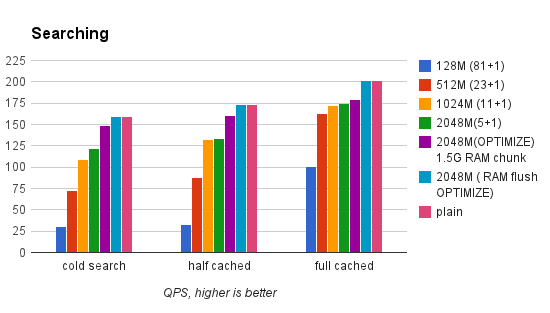
- 一是增量索引只能定时创建,必须会造成数据到主索引时存在一个时间差,而且经测试,增量索引merge到主索引时还经常会被阻塞一段时间(–rotate);
- 二是在增量索引中无法对字符串属性进行修改UPDATE,所以发布的物品修改了名称就甭想搜索到了。
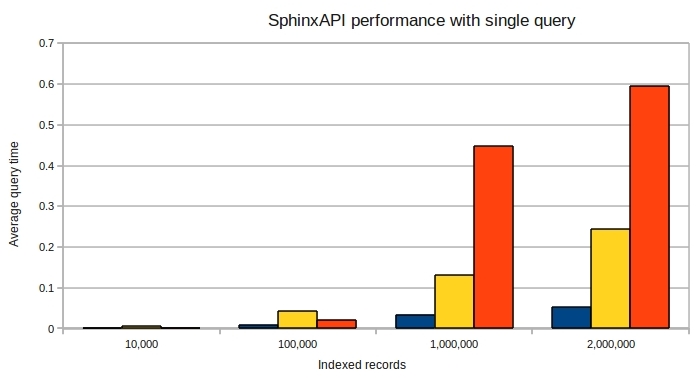
红色为rt索引,蓝色为plain索引。
主要差距来自于rt实时索引在超出rt_mem_limit 之后就会将内存中的内容RAM CHUNK写入磁盘块DISK CHUNK,当多次写入磁盘块后,每次搜索的结果都需要从多个磁盘块中读取,然后再合并结果。当然这可以通过加大rt_mem_limit来解决:
但OPTIMIZE不但需要大量IO,也需要大量CPU时间,因为它需要读取多个CHUNK,然后再合并结果。
- 一旦修改了数据库表结构,那要修改rt索引中的数据也是比较麻烦的,需要手工修改。
综上所述,纯使用sphinx的rt索引还是比较娇贵的。我一直想把rt索引的实时和可修改字符串优势与plain索引的快速创建优势结合起来,经过不断查看官方文档,我找到了一个兼顾两者优点的方案。
就是:创一个每日定时任务,在夜里创建全量plain索引,然后将全量索引TRUNCATE,同时将plain索引ATTACH 到rt实时索引,随后只在rt索引中搜索和修改(在修改DB中的数据后)。
这样做的优点我们最后来看。下面先用实例来演示一遍—————:
假设我们有一个求购表,叫ask_buy,简化的表结构为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
CREATETABLE `ask_buy` (
`id` INT(11) NOTNULL AUTO_INCREMENT,
`title` VARCHAR(200) NOTNULL,
`deleted` TINYINT(1) NOTNULLDEFAULT'0',
PRIMARYKEY (`id`),
)
COMMENT='求购'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;
CREATE TABLE `ask_buy` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` VARCHAR(200) NOT NULL,
`deleted` TINYINT(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
)
COMMENT='求购'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
source ask_buy_src
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = root
sql_db = taoquan
sql_port = 3306 # optional, default is 3306
sql_query_pre = SET NAMES utf8
sql_query_pre = SET SESSION query_cache_type=OFF
sql_query = SELECT id, title, deleted FROM t_ask_buy
sql_attr_uint = deleted
sql_field_string = title
sql_query_post_index = REPLACE INTO search_counter SELECT 'ask_buy',MAX(id) FROM ask_buy
sql_ranged_throttle = 0
}
index ask_buy
{
type = plain
source = ask_buy_src
path = /usr/local/sphinx/data/ask_buy
docinfo = extern
dict = keywords
mlock = 0
morphology = none
min_word_len = 1
ngram_len = 1
ngram_chars = U+3000..U+2FA1F
html_strip = 0
}
index rt_ask_buy
{
type = rt
path = /usr/local/sphinx/var/data/rt_ask_buy
rt_mem_limit = 512M
rt_field = title
rt_attr_uint = deleted
}
source ask_buy_src
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = root
sql_db = taoquan
sql_port = 3306 # optional, default is 3306
sql_query_pre = SET NAMES utf8
sql_query_pre = SET SESSION query_cache_type=OFF
sql_query = SELECT id, title, deleted FROM t_ask_buy
sql_attr_uint = deleted
sql_field_string = title
sql_query_post_index = REPLACE INTO search_counter SELECT 'ask_buy',MAX(id) FROM ask_buy
sql_ranged_throttle = 0
}
index ask_buy
{
type = plain
source = ask_buy_src
path = /usr/local/sphinx/data/ask_buy
docinfo = extern
dict = keywords
mlock = 0
morphology = none
min_word_len = 1
ngram_len = 1
ngram_chars = U+3000..U+2FA1F
html_strip = 0
}
index rt_ask_buy
{
type = rt
path = /usr/local/sphinx/var/data/rt_ask_buy
rt_mem_limit = 512M
rt_field = title
rt_attr_uint = deleted
}
|
- 然后创建一个脚本index.sh来创建plain全量索引并ATTACH到rt索引:
1
2
3
4
5
6
|
#!/bin/bash
/usr/local/sphinx/bin/indexer goods --rotate --all >> /usr/local/sphinx/var/log/index_rt.log
mysql -P 9306 -h 127.0.0.1 -e"TRUNCATE RTINDEX rt_ask_buy;ATTACH INDEX ask_buy TO RTINDEX rt_ask_buy;"
#!/bin/bash
/usr/local/sphinx/bin/indexer goods --rotate --all >> /usr/local/sphinx/var/log/index_rt.log
mysql -P 9306 -h 127.0.0.1 -e"TRUNCATE RTINDEX rt_ask_buy;ATTACH INDEX ask_buy TO RTINDEX rt_ask_buy;"
|
1
2
|
30 2 * * * sudo ~/index.sh
30 2 * * * sudo ~/index.sh
|
优点:
- 这样rt索引就无需定期flush到磁盘,因为即便它丢失了也可以直接进行重建,而且重建后还没有碎片。
- 还测试了,如果修改了表结构,只要修改sphinx配置文件,然后重启searchd进程,最后再执行index.sh即可。
- 如果sphinx崩溃,只需要再执行index.sh即可,无需从binlog或dump中恢复到rt索引,直接从数据源重建索引的速度是很快的:
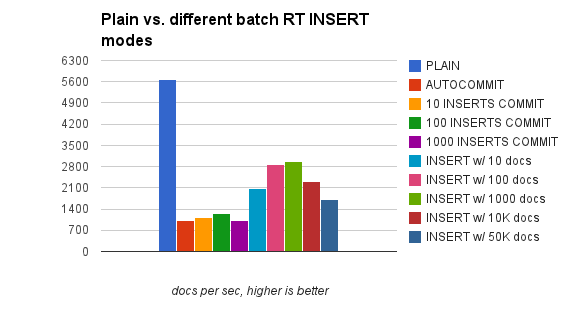
- 这种方案的检索速度比plain方案相当,因为全量索引的DISK CHUNK只有一个,而只要rt_mem_limit设置合理,每天新增的DISK CHUNK也不会很多,这样在一两个CHUNK之间合并,速度只比纯plain方案略低。参考下图的2048M(5+1),重点不在2048M,而在后面的5+1,即5个DISK CHUNK+1个RAM CHUNK。